

 ggplot2 수평 막대그래프 그리기(수평막대차트)
ggplot2 수평 막대그래프 그리기(수평막대차트)
수평 막대그래프를 그리는 방법중의 하나를 정리해본다. 아래 왼편그림처럼 수직차트를 그려놓고, x/y 축을 뒤집어 바꾸어 오른쪽 그림처럼 변경이 가능하다. 그 기능을 제공하는 ggplot2::coord_flip 함수를 사용하면 된다. 테스트를 진행할 임시 데이터를 하나 만든다. 연도별 통계를 임의로 만들어본다. x축은 년도이고, y축은 50~150 사이의 숫자를 랜덤하게 만들어본다. library(tidyverse) tb = tibble(x = 2017:2022, y = sample(50:150, 6)) %>% mutate(z = max(y) == y) # A tibble: 6 × 3 x y z 1 2017 97 FALSE 2 2018 101 FALSE 3 2019 146 TRUE 4 2020 110 FA..
 ggplot2 막대그래프 위에 숫자, 수치 표시하기
ggplot2 막대그래프 위에 숫자, 수치 표시하기
막대그래프를 그릴때, 막대위에 숫자표기를 하고 싶다면, 쉽게 설정이 가능하다. 그리고 왼편의 ggplot 에서 흔히 보는 막대그래프 스타일을 오른편의 그래프로 디자인까지 진행해본다. 임의의 데이터 셋을 만든다. sample 을 이용해서 랜덤으로 값을 추출한다. tb = tibble(x = 1:5, y = sample(200:240, 5), l = c("서울", "경기", "강원", "충청", "제주")) 아래 2줄만으로도 막대그래프를 손쉽게 만들 수 있다. ggplot(tb, aes(x, y)) + geom_col(width = 0.6) 막대그래프 위에 실제 y 값을 표시하려면, 추가적인 설정이 필요하다. geom_text 를 이용해서 텍스트를 추가하면 되고, vjust 설정으로 위아래로 위치를 살짝씩 ..
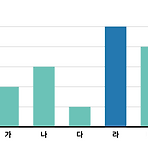 ggplot2 그래프 한글깨짐 오류 해결. 폰트 설정 방법
ggplot2 그래프 한글깨짐 오류 해결. 폰트 설정 방법
막대그래프를 ggplot 으로 막대그래프를 표현하다가 한글로 x 축을 한글로 가~마 로 설정하고, y 축 근처에 (단위) 문구를 넣고 싶었다. 하지만 별다른 설정을 하지 않으면 아래와 같은 한글깨짐 현상을 보게 될지도 모른다. ggplot 을 쓰려는데 한글을 못쓸리 없다. 열심히 해결책을 찾아 본다. 우선 사전작업이 하나 있는데, 아래의 extrafont 라이브러리를 설치하고, 컴퓨터에 설치된 폰트를 불러온다. install.packages("extrafont") library(extrafont) font_import() 그리고, 그래프를 만들 데이터를 정의한다. tb = tibble(x = 1:5, y = c(10,15,5,25,20), l = c("가", "나", "다", "라", "마")) %>% ..
 원형차트, 도넛차트 시작 위치 & 각도 조정하기
원형차트, 도넛차트 시작 위치 & 각도 조정하기
r 프로그래밍 언어로 원그래프/도넛차트를 그릴때, 어느 위치부터 값을 그릴지 셋팅하는 걸 정리해본다. 저번에 ggplot 으로 파이차트와 도넛차트를 그려보았다. 항상 0 이 12시 위치에서 시작할 수 밖에 없는지 의구심이 들었는데 역시 다른 위치/각도에서 시작할 수 있는 옵션이 있었다. 우선 도넛차트 그리는 법은 아래 포스팅을 참고한다. (ggplot2) R 프로그래밍 파이차트/도넛차트 예제 오늘은 파이차트(원모양의 그래프, 원그래프) 혹은 가운데가 비어있는 도넛차트를 만들어보려 한다. 기본 데이터셋인 mtcars 를 활용해서 우선 bar 차트를 만들어야 한다. 여기서 중요한건, factor emflant.tistory.com 이전 포스팅에서보면 coord_polar 함수로 원형차트와 도넛차트를 그렸었는..
 (ggplot2) R 프로그래밍 파이차트/도넛차트 예제
(ggplot2) R 프로그래밍 파이차트/도넛차트 예제
오늘은 파이차트(원모양의 그래프, 원그래프) 혹은 가운데가 비어있는 도넛차트를 만들어보려 한다. 기본 데이터셋인 mtcars 를 활용해서 우선 bar 차트를 만들어야 한다. 여기서 중요한건, factor 로 x축을 만들면 안되고, 숫자형으로 정의 되어야 한다. 만들고나면 화면에 꽉찬 막대그래프가 그려진다. library(tidyverse) ggplot(mtcars, aes(x = 1, fill = factor(cyl))) + geom_bar() 원형그래프(Pie chart) 아까 만든 막대그래프를 원형으로 돌돌 말아본다고 생각하면 쉽다. coord_polar 로 무슨 축을 기준으로 원형으로 표현할지 정한다. 손쉽게 파이차트(원그래프)가 만들어진다. ggplot(mtcars, aes(x = 1, fill ..
 (ggplot2) 표준정규분포표, 확률밀도함수를 R 그래프로 구현하기
(ggplot2) 표준정규분포표, 확률밀도함수를 R 그래프로 구현하기
ggplot2 로 정규분포표, 확률밀도함수 그래프를 그려보기로 한다. 아래 그림은 인터넷 서핑해서 구해놓은 그래프인데, R - ggplot2 로 똑같이 구현할 예정이다. 그래프만 그리는 건 아니고, 화살표며 f(x) 같은 수식 등 다 넣어보려 한다. 분포함수, 확률밀도함수 하기전에 알아야 할 몇가지 함수가 있다. dnorm, pnorm, qnorm 을 알아야 한다. 위 그래프 기준으로 우선 참고해서 이해하면 쉽다. # x축의 값을 입력하면, 확률밀도함수의 f(x) 의 값을 리턴. dnorm(1) # [1] 0.2419707 --> y 값을 뜻함. # x축의 값을 입력하면, x값이하의 f(x)의 적분값(확률밀도함수의 넓이)를 리턴 pnorm(1) # [1] 0.8413447 --> x 약 x = 1 이 리..
 이클립스 프로젝트 불러오기 및 열기, import
이클립스 프로젝트 불러오기 및 열기, import
이클립스에서 항상 헤매고 애먹는게 하나 있는데, 프로젝트 파일들을 누군가한테 받든 어디서 다운받았던 간에, 현재 이클립스 작업창에 프로젝트로 불러오고 싶은데 어디서 무얼해야하는지 난감한 경우가 있다. 넷빈같은 경우 아예 open project 메뉴가 제일 밖의 메뉴에 보이는데 이클립스는 숨어있기 때문에 어려워보일 수도 있다. 어쨋든 다른 컴퓨터에서 이클립스로 개발했던 프로젝트를 받을 때 그냥 폴더 채로 받거나 zip 으로 묶어서 받았었을 수도 있다. 그 경우 이클립스에서 프로젝트를 어떻게 여는지 알아보자. 항상 주의 해야할 것은 원본은 항상 어딘가가 따로 저장해놓으시길 바란다. 예상치 못한 결과가 있을 수 있다. 보다시피 현재 열려있는 프로젝트는 ajax-sample 하나 뿐이다. 각자 자신의 이클립스 ..
 (R 그래프) ggplot::geom_text - Bar 차트/막대 그래프 레이블 표시 예제
(R 그래프) ggplot::geom_text - Bar 차트/막대 그래프 레이블 표시 예제
아래와 같은 막대그래프를 하나 그려보면서 공부한걸 정리해본다. 간단해 보이지만, 막대그래프를 y 축을 기준으로 표현했고, 하나의 값으로 그린게 아니라 여러값을 그룹핑하여 쌓아(stacked) 표현했고, 마지막으로 수치들을 막대그래프 위에 혹은 우측에 텍스트로 표현하는 것까지 구현해야 한다. 그래프를 그리고자하는 스킬보다는 데이터를 이해하는게 더 중요하다. 아래와 같은 그룹형으로 스택(stacked)형의 막대를 쌓기 위해서는 기본적으로 수치간에 그룹핑을 할 수 있는 값들이 추가로 필요하다. 여기서 date 는 양배추 심은 일자, cultivar 는 양배추 품종, weight 양배추 수확 무게 인듯 하다. 어쨋든 일자별로 심은 품종별로 무게를 bar 차트로 구현하는게 목적이며, 그 그룹핑을 할 수 있는 컬럼..
- Total
- Today
- Yesterday
- Spring
- ggplot
- 셀프개통
- ggplot2
- 마인크래프트
- github
- 맥북
- python
- 알뜰요금제
- 막대그래프
- docker
- eclipse
- SVN
- ipTIME
- 도넛차트
- R
- 아이맥
- 자급제폰
- Google Chart Tools
- ubuntu
- ktm모바일
- MongoDB
- vagrant
- MySQL
- MyBatis
- java
- 이클립스
- Oracle
- javascript
- heroku
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |